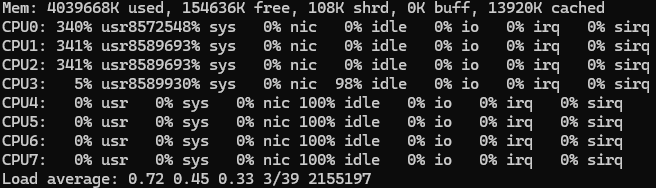
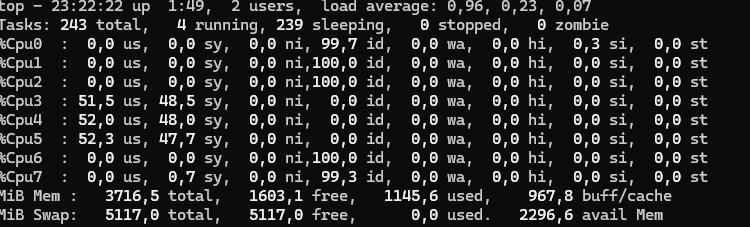
Myslím, že se jedná o chybu v jádře. Na node22(kernel 6.6.1) mi to reportuje vytížení i jiných jader(je jedno jaký jádro nastavím tak to začiná na jádře 0 a na playground(6.6.10) to ukazuje vytížení jen jednoho(v top i třeba 3000%).
Někdo kdo o tom ví víc se určitě ozve.
Podle mě to je nějaká větší chybka(která se nese už delší dobu, jen s posledníma verzema to je ještě horší) a reportuje to špatný jádra (na tom starším jádře) který jsou vytížený.
V KVM který má vlastní jádro to reportuje dobře.
použil jsem toto pro testování
Taskset hlavne na nasem kernelu nema vubec zadny efekt, proces si bude vesele cestovat mezi jadry dal. U nas neni zadna moznost pinovat procesy nikam, je to tak naschval, protoze je to sdilena masina, nikdo nema zadna dedikovana jadra a pinning tak muze akorat prinest problemy, ale nic pozitivniho.
Na ten bug se podivam (btw je to mensi! chyba! - kotatka to nezere, vsiml si toho nekdo az po hm, pul roce v produkci, minimalne, cili se to netyka vsech, jenom kdyz se snazi nekdo delat takovyhle chytrystiky, co na sdilenych masinach nedavaji smysl tak, jako tak :D)
Jeste dodam, ze je to tak hlavne proto, ze ten pinning (treba, ale ne jenom) Java dela automaticky a tak vsechny javy na celem stroji byly pinned na prvnich 8mi jadrech a zbytek o JVM neslysel, to byl primarni duvod, proc jsme cpu pinning modifikovali tak, ze nic nedela. Jadro si zapamatuje cpu masku, ktera byla procesu nastavena a tu pak na vyzadani vraci zpatky, ale treba v /proc/pid/stat to cislo jadra, kde proces bezel naposled, virtualizovane neni. I v tom topu, kdyz se prida kolonka na posledni CPU jadro, je to pak videt, ze jich ten proces navstivi o dost vic, nez co ma pinned.
To virtualizovani spotrebovaneho casu je docela netrivialni zalezitost, zrejme mi tam unikl nejaky edge-case, co se poji prave s tim pinovanim. Cili diky za report, tohle by mi melo uplne stacit, abych prisel na to, cim to je. My to sice v jadre mame uz nejakou dobu, ale jelikoz to v prvnim levelu namespaces/cgroups krylo LXCFS, bylo to videt az v dalsich (Dockerech a jinych vnorenych kontejnerech), kde si toho asi moc lidi nevsimlo.
To virtualizovani statistiky zatizeni CPU ted funguje tak, ze v momente, kdy se userspace proces dotaze na vyuziti CPU pres /proc/stat, se vezmou statistiky z cpuacct cgroupy, ktera je korenova pro to VPS, spocte se vsechen vyuzity cas a pak se podeli casem od posledniho vycitani, cim dostaneme cislo, ktere vyjadruje, za kolik plne obsazenych CPU jader na tu danou periodu to bylo casu. Potom se jde po tech virtualnich jadrech od nuly a pripocitava se jim ten vyuzity cas rozdeleny v pomeru %usr a %sys, v kterem to bylo podle cpuacct cgroup spotrebovane, az se dojde k poslednimu jadru, kteremu se pripocita zbytek.
Ze se pripocte nejak hodne k prvnimu jadru musi znamenat, ze jsem tam budto ted nekdy zanesl nejakou zmenu, ktera mi zbourala predchozi predpoklady, nebo je tam jeste nejaky faktor, o kterem zatim nevim. Dosnidam a podivam se na to.
Strelil jsem se do nohy sam, no… v predchozich verzich toho CPU-schovavajiciho patche jsem zmenil semantiku fake_cpumask tak, ze jsem znemoznil pouziti na zjisteni nastavene affinity masky zpatky; tak jsem to ted splitnul, aby bylo jasne, co ktera z nich dela, fake_online_cpumask dava jadra 0 az N podle cpulimitu, fake_affinity_cpumask vraci masku nastavenou pres sched_setaffinity().
Taky jsem poznal live-patching o kus detailneji, uz si ta nase kpatch-build-based masinerie ve vpsAdminOS poradi s __init sekcemi tak, ze nevyErroruje, ale proste to preskoci (tenhle patch treba by bylo potreba zasadne prekopat, aby nezasahnul do zadnych funkci marked jako __init).